2,516 Views
2,516 Views ระบบฐานข้อมูลแบบรวมศูนย์ (Centralized Database System) ประกอบด้วยฐานข้อมูล ซอฟต์แวร์จัดการฐานข้อมูล และหน่วยความจำที่ใช้ในการจัดเก็บฐานข้อมูลซึ่งอาจจะเป็นจานบันทึก (Disk) สำหรับการจัดเก็บแบบเชื่อมตรง (on-line) หรืออาจจะเป็นแถบบันทึก (Tape) สำหรับการจัดเก็บแบบไม่เชื่อมตรง (off-line) เพื่อใช้เป็นหน่วยเก็บสำรอง ระบบฐานข้อมูลแบบนี้สามารถถูกเรียกใช้งานได้จากจุดอื่น ๆ ที่มีเครื่องปลายทาง (Terminal) ประจำอยู่แต่ละฐานข้อมูลและซอฟต์แวร์จะอยู่รวมกันที่จุดเดียวเท่านั้นซึ่งเมื่อระบบคอมพิวเตอร์เจริญมากขึ้นพร้อมทั้งพัฒนาการในเรื่องเครือข่ายสำหรับการติดต่อดีมากขึ้นทำให้มีการศึกษาและพัฒนาระบบฐานข้อมูลแบบกระจายขึ้น เหตุจูงใจสำหรับการพัฒนาฐานข้อมูลแบบกระจายมีอยู่ด้วยกันหลายประการ ได้แก่
๑. งานฐานข้อมูลบางอย่างมีข้อมูลกระจัดกระจายอยู่ตามแหล่งต่าง ๆ หน่วยงานบางแห่งอาจจะมีสาขาอยู่ตามจังหวัด ตัวอย่างเช่น ธนาคารจะมีสาขาอยู่ทั่วประเทศข้อมูลของแต่ละสาขาก็จะถูกเก็บไว้ที่สาขานั้น ๆ แต่ในบางครั้งผู้บริหารหน่วยงานที่ส่วนกลางอาจต้องการข้อมูลสรุปซึ่งต้องใช้ข้อมูลจากหลาย ๆ สาขาทั่วประเทศ ซึ่งในกรณีนี้ระบบจัดการฐานข้อมูลควรจะมีความสามารถในการดึงข้อมูลจากสาขาต่าง ๆ ได้ด้วย
๒. เพิ่มความน่าเชื่อถือและความทันสมัยของข้อมูล สำหรับข้อมูลที่กระจายอยู่ตามจุดต่าง ๆ เมื่อมีการเปลี่ยนแปลงค่าของข้อมูล ณ จุดนั้น ข้อมูลใหม่จะถูกบันทึกแทนข้อมูลเก่าทันทีและสามารถนำมาใช้งานได้ ณ เวลานั้นเนื่องจากซอฟต์แวร์สำหรับจัดการฐานข้อมูลกระจายอยู่ตามจุดต่าง ๆ นอกจากนี้ถ้าระบบในบางจุดย่อยเสียหายและไม่สามารถทำงานได้ระบบ ณ จุดอื่น ๆ ก็ยังคงสามารถทำงานต่อไปได้แต่ถ้าเป็นแบบรวมศูนย์เมื่อระบบเสียหายเครื่องปลายทางใด ๆ ก็ไม่สามารถทำงานได้เลย
๓. เพื่อควบคุมการเข้าใช้ข้อมูลทั้งนี้เนื่องจากข้อมูลกระจัดกระจายอยู่ตามจุดต่าง ๆ ทำให้ผู้ดูแลระบบสามารถกำหนดได้ว่าผู้ใช้จากจุดใดสามารถเข้าใช้ข้อมูลจากจุดใดได้บ้างและได้มากระดับใดด้วย
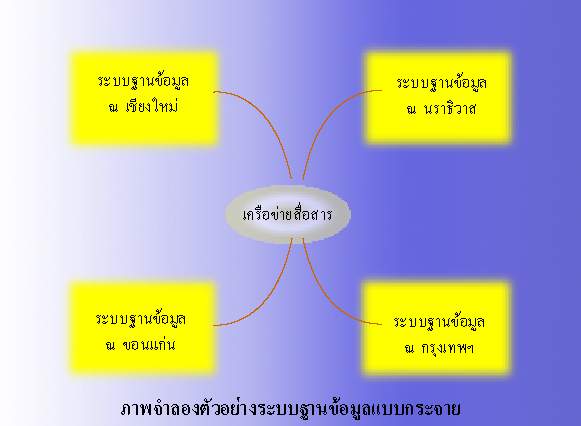
๔. เพิ่มประสิทธิภาพการทำงานเมื่อมีการกระจายข้อมูลตามจุดต่าง ๆ จะส่งผลให้ฐานข้อมูลย่อยแต่ละจุดมีขนาดเล็กลงซึ่งทำให้เมื่อมีการสอบถามข้อมูลในแต่ละฐานข้อมูลย่อยการค้นหาข้อมูล ย่อมทำได้รวดเร็วขึ้น นอกจากนี้ผู้ใช้ก็กระจายอยู่ตามจุดต่าง ๆ แต่ละจุดจึงสามารถทำงานขนานกันได้เลยซึ่งไม่เหมือนกับระบบรวมศูนย์ที่จะต้องส่งทุก ๆ คำสั่งไปที่เดียวกันหมดและทำให้ต้องรอลำดับในการทำงานเพราะไม่สามารถทำงานพร้อม ๆ กันได้
ระบบฐานข้อมูลแบบกระจายประกอบด้วยกลุ่มของระบบฐานข้อมูลย่อยติดต่อสื่อสารกันโดยผ่านเครือข่ายสื่อสารโดยที่แต่ละระบบฐานข้อมูลย่อยสามารถทำงานได้ด้วยตนเองและยังสามารถให้ผู้ใช้จากจุดอื่น ๆ เข้ามาใช้ข้อมูลในฐานข้อมูลได้ตามข้อตกลงโดยผู้ใช้จะไม่รู้สึกถึงการกระจายของข้อมูลเลย ทั้งนี้องค์ประกอบหลักของระบบฐานข้อมูลแบบกระจายประกอบด้วยลักษณะที่สำคัญ ๑๒ ประการ ได้แก่
๑. ภาวะอิสระเฉพาะที่ (Local Autonomy) คือ สภาวะที่คำสั่งต่าง ๆ ในจุด ก สามารถทำงานและควบคุมได้ โดยจุด ก ไม่ต้องขึ้นอยู่กับคำสั่งจากจุดอื่นรวมถึงข้อมูลในจุด ก ควรถูกควบคุมจัดการ และเป็นเจ้าของด้วยจุด ก เท่านั้น
๒. ภาวะไม่ขึ้นกับหน่วยงานกลาง (No Reliance on a Central Site) ทุกจุดของระบบฐานข้อมูลย่อยมีความเสมอภาคกันนั่น คือ ไม่มีจุดใดที่ทำหน้าที่เป็นศูนย์กลางการทำงาน ในทางตรงข้ามถ้ามีจุดศูนย์กลางเมื่อมีการทำงานใด ๆ เกิดขึ้นก็จะต้องส่งผ่านมาที่จุดนี้ก่อนจึงส่งผลให้จุดนี้กลายเป็นคอขวด (bottleneck) ของการทำงานและเมื่อจุดศูนย์กลางเกิดการขัดข้องก็จะทำให้ทุกจุดของระบบใช้งานไม่ได้ไปด้วยซึ่งก่อให้เกิดผลเสียเป็นอย่างยิ่ง
๓. เพิ่มความน่าเชื่อถือ (Reliability) และ สภาพพร้อมใช้งาน (Availability) ระบบโดยรวมยังคงทำงานอยู่ตลอดเวลาไม่ว่าจะมีจุดย่อยจุดใดขัดข้องหรือไม่ โดยอาจจะทำงานได้เฉพาะบางจุดย่อยเท่านั้นและการทำซ้ำข้อมูลในบางจุดย่อยก็ยังช่วยเสริมสภาพพร้อมใช้งานให้ดีมากขึ้นด้วย
๔. ความไม่ขึ้นกับตำแหน่ง (Location Independence) คือ ภาวะที่ผู้ใช้ไม่จำเป็นต้องรู้ว่าข้อมูลใดจัดเก็บอยู่ที่จุดใด ผู้ใช้สามารถจะเรียกใช้ข้อมูลได้เสมือนว่าข้อมูลทั้งหมดอยู่ที่จุดที่ผู้ใช้กำลังใช้งาน เพื่อให้ง่ายและสะดวกในการใช้งาน
๕. ความไม่ขึ้นกับการแตกกระจาย (Fragmentation Independence) ระบบฐานข้อมูลแบบกระจายควรจะมีการแตกกระจายข้อมูล (Data Fragmentation) ซึ่งก็ คือ การแตกข้อมูลในตารางความสัมพันธ์ออกเป็นตารางย่อย ๆ กระจายอยู่ตามจุดต่าง ๆ ตามการใช้งาน การแตกกระจายนี้มี ๒ แบบ คือ แนวนอน (horizontal) และ แนวตั้ง (vertical) เป็นการแยกข้อมูลตามข้อจำกัดของแต่ละระเบียนหรือการแยกข้อมูลตามสดมภ์และตามลำดับ การไม่ขึ้นกับการแตกกระจายก็คือการที่ผู้ใช้สามารถใช้งานได้เสมือนไม่มีการแตกกระจายข้อมูลเลยซึ่งส่งผลให้การใช้งานง่ายขึ้น
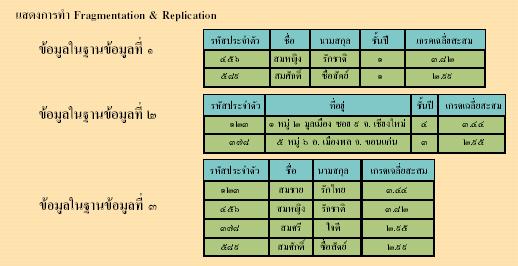
๖. ความไม่ขึ้นกับการทำซ้ำ (Replication Independence) การทำซ้ำข้อมูล (Data Replication) คือ การทำซ้ำข้อมูลของตารางสัมพันธ์ไว้ในหลาย ๆ จุด ซึ่งจะมีประโยชน์ คือ ประสิทธิภาพในการทำงานเพิ่มขึ้นเนื่องจากสามารถทำงานได้ ณ จุดย่อยที่เรียกใช้ได้เลยและเป็นการประหยัดการติดต่อสื่อสารระหว่างจุดด้วย นอกจากนี้ยังเป็นการเพิ่มสภาพความพร้อมในการใช้งานด้วยเมื่อจุดย่อยจุดใดขัดข้องข้อมูลชุดเดียวกัน ณ จุดย่อยอื่นก็ยังสามารถนำมาใช้งานแทนกันได้ ดังนั้นความไม่ขึ้นกับการทำซ้ำ คือ การที่ผู้ใช้งานไม่รู้สึกถึงการทำซ้ำข้อมูลในการใช้งานข้อมูลซึ่งส่งผลให้การใช้งานเป็นไปโดยง่ายยิ่งขึ้น
๗. การประมวลผลข้อคำถามแบบกระจาย (Distributed Query Processing) แบบจำลองข้อมูลเชิงสัมพันธ์มีความเหมาะสมสำหรับระบบฐานข้อมูลแบบกระจายเป็นอย่างยิ่งเมื่อพิจารณาในแง่การประมวลผลข้อคำถามด้วยเหตุผล ๒ ประการ คือ ภาษาสอบถามของแบบจำลองนี้เป็นภาษาขั้นสูงซึ่งทำการดึงข้อมูลจากฐานข้อมูลครั้งละกลุ่มข้อมูล แต่ถ้าเป็นภาษาสอบถามขั้นต่ำจะทำงานครั้งละระเบียนข้อมูล เมื่อเป็นการทำงานแบบกระจายที่ต้องดึงข้อมูลจากจุดอื่น ๆ ซึ่งดึงได้เพียงครั้งละ ๑ ระเบียน ค่าใช้จ่ายในการติดต่อก็จะสูงมาก เหตุผลอีกประการหนึ่ง คือ แบบจำลองข้อมูลเชิงสัมพันธ์มีการหาวิธีการที่เหมาะสมที่สุดในการประมวลผลคำถามแต่ละข้อซึ่งทำให้การประมวลผลเป็นไปอย่างมีประสิทธิภาพที่สุด
๘. การจัดการรายการเปลี่ยนแปลงแบบกระจาย (Distributed Transaction Management) เกี่ยวข้องกับ ๒ กระบวนการ คือ การควบคุมการกู้ (Recovery Control) ทั้ง ๒ กระบวนการจะต้องมีการปรับปรุงเพิ่มขึ้นเมื่อนำมาใช้กับระบบฐานข้อมูลแบบกระจาย สำหรับการควบคุมการกู้นั้นวิธีการที่นำมาใช้แก้ปัญหา คือ โพรโทคอลสำหรับการคอมมิตแบบ ๒ ระยะ (Two-phase Commit Protocol) ส่วนเทคนิคในการควบคุมภาวะพร้อมกันที่นิยมใช้กันมาก คือ การใช้ตัวปิดกั้น (Locking) ทั้ง ๒ เทคนิคมีพื้นฐานในการทำงานบนระบบฐานข้อมูลแบบรวมศูนย์ซึ่งเมื่อนำมาใช้กับระบบฐานข้อมูลแบบ กระจายก็ต้องมีการปรับปรุงเทคนิคเพื่อให้สามารถทำงานกับระบบใหม่ได้อย่างมีประสิทธิภาพ
๙. ความไม่ขึ้นกับฮาร์ดแวร์ (Hardware Independence) ระบบฐานข้อมูลแบบกระจายมักจะประกอบไปด้วยฮาร์ดแวร์ที่แตกต่างกันในแต่ละจุดของการทำงานซึ่งระบบควรทำงานร่วมกันได้นั่น คือ ระบบจัดการฐานข้อมูลเดียวกันควรที่จะทำงานได้บนฮาร์ดแวร์ที่ต่างกันและฮาร์ดแวร์ในทุก ๆ จุดควรมีความเสมอภาคกันในการทำงาน
๑๐. ความไม่ขึ้นกับระบบปฏิบัติการ (Operating System Independence) ระบบการจัดการฐานข้อมูลที่นำมาใช้ในฐานข้อมูลแบบกระจายควรจะมีความสามารถที่จะทำงานบนระบบปฏิบัติการที่แตกต่างกันได้
๑๑. ความไม่ขึ้นกับเครือข่าย (Network Independence) ระบบฐานข้อมูลแบบกระจายที่ดีควรจะทำงานได้บนฮาร์ดแวร์หลาย ๆ แบบและระบบปฏิบัติการหลาย ๆ แบบ นอกจากนี้ก็ควรที่จะทำงานได้บนเครือข่ายสื่อสารหลาย ๆ แบบด้วย
๑๒. ความไม่ขึ้นกับระบบจัดการฐานข้อมูล (DBMS Independence) ระบบฐานข้อมูลแบบกระจายจะมีความสมบูรณ์มากขึ้นเมื่อแต่ละจุดทำงาน สามารถใช้ระบบจัดการฐานข้อมูลที่แตกต่างกันได้ โดยอาจจะพัฒนาส่วนต่อประสาน (Interface) ให้สามารถเชื่อมต่อการใช้งานระหว่างระบบจัดการฐานข้อมูลที่แตกต่างกันได้ ตัวอย่าง เช่น กรณีระบบจัดการฐานข้อมูลโอราเคิลกับไซเบสซึ่งสนับสนุนมาตรฐานเอสคิวแอลเดียวกันแต่ใช้งานอยู่ ณ จุดทำงานต่างกัน ระบบฐานข้อมูลแบบกระจายทั้งสองสามารถทำงานร่วมกันได้โดยผ่านส่วนประสานงานเอสคิวแอล เป็นต้น
อย่างไรก็ตามการพัฒนาระบบจัดการฐานข้อมูลแบบกระจายจะต้องมีความซับซ้อนเพิ่มขึ้น ซอฟต์แวร์สำหรับจัดการฐานข้อมูลแบบกระจาย (Distributed Database Management Systems : DDBMS) ควรที่จะมีฟังก์ชันพิเศษเพิ่มขึ้น ดังนี้
๑. ฟังก์ชันในการเข้าถึงข้อมูลในจุดอื่น การส่งคำสั่งตอบคำถามและส่งข้อมูลระหว่างจุดได้โดยผ่านเครือข่ายสื่อสาร (Communication Network)
๒. ฟังก์ชันในการเก็บรายละเอียดของข้อมูลว่าข้อมูลใดกระจายอยู่ที่จุดใดบ้าง ทั้งนี้เพื่อใช้ในการปรับปรุงแก้ไขข้อมูลให้ถูกต้องและสอดคล้องกัน
๓. ฟังก์ชันในการทำให้ข้อมูลที่ถูกทำซ้ำในจุดต่าง ๆ มีความถูกต้องและสอดคล้องกันเสมอ
๔. ฟังก์ชันในการเลือกชุดข้อมูลที่ควรจะใช้เมื่อข้อมูลชุดนั้นมีการทำซ้ำไว้หลายตำแหน่ง
๕. ฟังก์ชันในการปรับคำสั่งสอบถามที่ต้องการใช้ข้อมูลจากหลาย ๆ จุด
๖. ฟังก์ชันในการกู้ (Recovery) ข้อมูลคืนเมื่อจุดใดจุดหนึ่งในระบบขัดข้อง (crash)
สถาปัตยกรรมแบบรับ-ให้บริการ (Client-Server Architecture) พัฒนาขึ้นมาเพื่อใช้กับระบบที่มีคอมพิวเตอร์จำนวนมากและติดต่อกันโดยผ่านเครือข่ายสื่อสาร ระบบนี้ได้รับความนิยมเพิ่มมากขึ้น ในการนำมาพัฒนาใช้กับระบบจัดการฐานข้อมูลแบบกระจายเนื่องจากมีความสามารถในการสนับสนุนในการทำงานแบบกระจายแนวคิด คือ การแบ่งซอฟต์แวร์จัดการฐานข้อมูลออกเป็น ๒ ระดับ คือ ระดับบริการและระดับให้บริการเพื่อลดความซับซ้อนของระบบลง บางจุดอาจจะทำหน้าที่เป็นผู้รับบริการเพียงอย่างเดียวในขณะที่จุดอื่นอาจทำหน้าที่เป็นผู้ให้บริการซึ่งจะมีเฉพาะซอฟต์แวร์ที่ทำหน้าที่เป็นผู้ให้บริการเท่านั้นหรือในบางจุดอาจมีทั้งส่วนให้บริการและรับบริการอยู่ร่วมกันก็ได้ ระบบฐานข้อมูลแบบกระจายแบ่งได้เป็นหลายประเภทด้วยกันซึ่งขึ้นอยู่กับปัจจัยที่เรานำมาพิจารณาเป็นเกณฑ์ในการจัดแบ่งตัวอย่างหลักเกณฑ์ในการแบ่งระบบฐานข้อมูลแบบกระจาย ได้แก่
๑. ระดับความเหมือน (Degree of Homogeneity) ของซอฟต์แวร์จัดการฐานข้อมูลแบบกระจาย กล่าวคือ ซอฟต์แวร์นี้ในทุก ๆ ระดับผู้ให้บริการเหมือนกันทั้งหมดหรือไม่และในระดับผู้รับบริการ เหมือนกันทั้งหมดหรือไม่
๒. ระดับภาวะอิสระเฉพาะที่ (Degree of Local Autonomy) ซึ่งพิจารณาว่าระบบฐานข้อมูลแบบกระจายนั้นสามารถทำงานบางอย่าง ณ จุดทำงานนั้น ๆ ได้บ้างหรือไม่
๓. ระดับความโปร่งใสของการกระจาย (Degree of Distribution Transparency) คือ การที่ผู้ใช้ระบบฐานข้อมูลแบบกระจายได้สัมผัสหรือรับรู้ถึงการแตกกระจายหรือการทำซ้ำของข้อมูลบ้างหรือไม่